Strange. I logged in to brihtertomorrowmap.com with no troubles. Which site was it you weren’t able to log in @dhruvmk?
It wasn’t the live site that I was having problems with - it was the source code. When I loaded it onto my local device and ran the application, it had some issues with login and signup
I suspect that’s related to the SSO settings in Discourse as those won’t be setup on your local environment, although I’m not sure.
Are you able to push the changes to the testing server and test them there?
@tmcnulty how’s the compiling issue looking?
@syl I was looking around to try and see what was wrong with the homepage of the site. It points to a dcs .json file but it’s a different one each time I log in.
Can you see any reason why its having a problem with all of them? ( -news, -happy, dcs-website.json, etc )
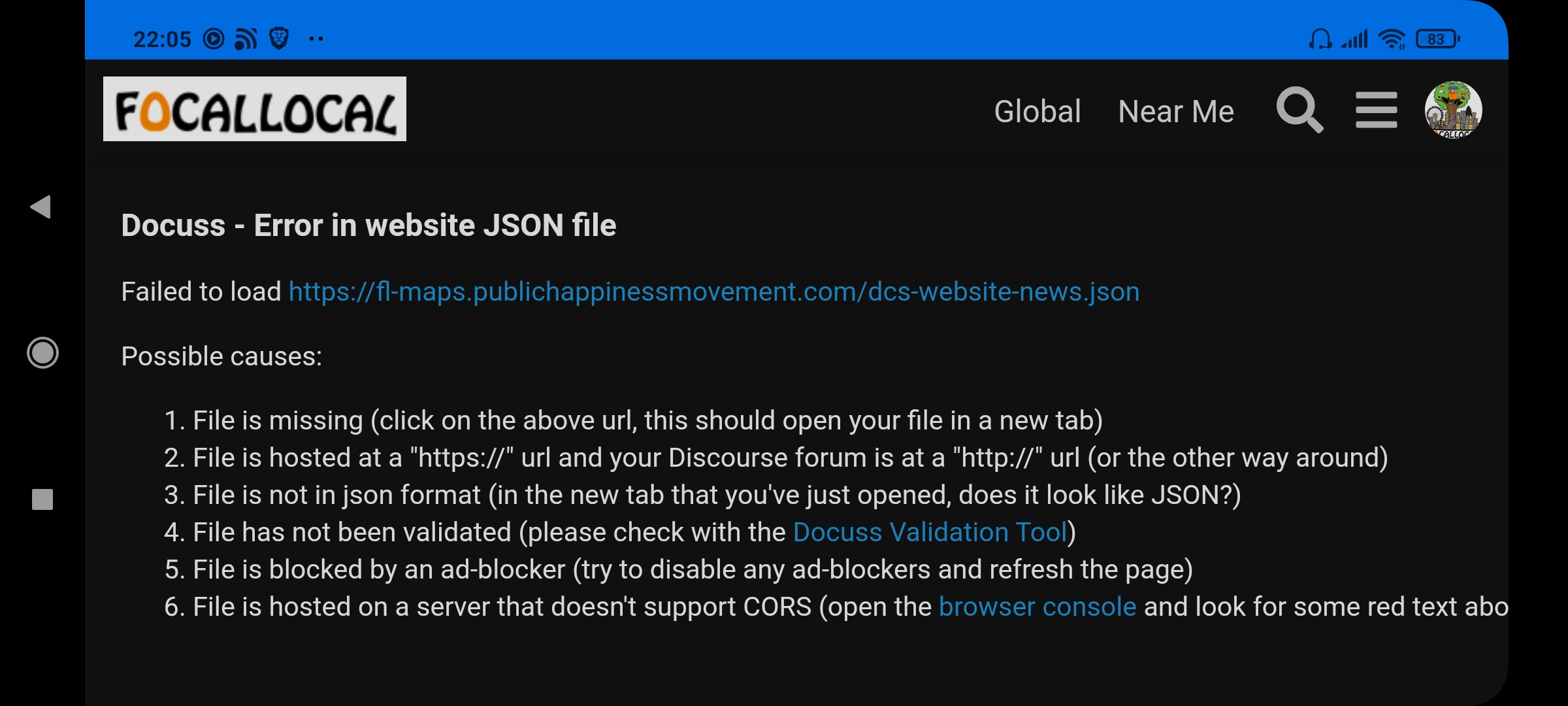
Sorry Syl I’m being stupid. It’s obviously because the app isn’t loading so it can’t see those files. Sorry for interrupting, and I hope both you and Docuss are doing well
@dhruvmk if you have a local Discourse instance set up it shouldn’t be too difficult to set up your own SSO settings. Just go into the admin section and type SSO, when you set it up you would have been asked to make an admin account.
If not you are likely to find it difficult which was why we set up the testing server, so waiting on Tom’s fix.
Hmm, alright. I don’t have a local Discourse instance atm, so I’ll just work on getting some of the React code in and then using the testing server.
That makes sense. I doubt login will work without Discourse
Hey, is the BTM site down too? The map seems to be unable to load when I’m logged in.
Yes. It looks like they all need to be recompiled and hopefully that is all.
The only other alternative i can think of is that something we rely on was outdated, or an automatic update from google or someone. Rebuilding them seems to be the most likely and 1st step.
Hey Andy,
I’m back to operational on the machine I use for development on this project. I screwed up again the same way I did last time though and lost the passphrase for the key our secrets are encrypted with. I generated a new one, saved, and backed up the passphrase in my cloud password manager. I asked @zofrex to update the key and once that’s done I’ll try to patch my changes.
I’m sorry about the delay. I’ve been working on patching kernel changes for Chromebook hardware security modules and the nature of the problem means every time it doesn’t work I lose the entire system, progress, everything. Hopefully my next will have some good progress.
Good luck 
@tmcnulty @dhruvmk How’s our progress going?
The marketing team have planned a campaign encouraging people to put boxes at all public transport stations with a sign asking people to put any (clean) socks they can spare into them for anyone in need to take. Socks are one of the most important items someone who is homeless can receive.
PHM is going to launch with a simple #CheerUpChallenge where people post up kind and supportive messages, take photos and them put them on our map so we can visualise how many people have joined in the wave of kindness 
@dhruvmk Tom has identified the sites main compiling error and i’ve sent an email to repair it. Hopefully everything should be up and running soon. Also, feel welcome to say hi to the new Team members joining in here if you’d like to encourage their efforts to support us: Introductions and Getting Started Chat
Hey Andy! So that’s good news - once the site is up and running, I can get the form completed. It’s almost done - only the UI needs to be created for the form. The i18n has been created and the Meteor has been connected to the new collection in Atlas.
Thats great news! Sorry i missed this message Dhruv. Also Tom thinks he’s identified the issue crashing the React side so we should hopefully get everything coming back up at around the same time!
And a few new team members joining in to build energy in here
@dhruvmk still no reply from them. I’ll follow up tomorrow, they have offered us the higher tier free. Maybe the guy forgot after our call
@WebDev ok i’ve got an update on when the platform will be running again. Donn at MongoDB says he’ll let us know the eta on Tuesday.
Longer than i was hoping but it is good news that they are on it!
![]()
Update on getting the sites back up and running:
We’ve been exploring options. Here’s a summary, if you understand any of these options and think you might be test them to get us back up and running please do let me know.
Upgraded to a higher Atlas plan by Mongo
I email Donn at MongoDB every week, and every week he says it’ll be resolved in a couple of days. I this point i don’t even know what to think as it’s been this cycle every week since Feb 12th now, and our sites are still down since the ill-fated migration.
Migrating our DB to a new provider
I found a kind hearted company that offered us free DB hosting run by @JordinParma. We explored switching but @tmcnulty says its a very big job as we’re not using an automated DB transferral as we were suggested to do to switch to Atlas when mlab closed down.
- Mongo instances need to be available, installed, containers, etc.
- They need all the same user/access configurations, and then we’d need to dump the existing instances and import them into the new ones
- Then update the applications to use the new servers
- Regardless of the host the underlaying database management will still be mongo
- Even when migrating away from atlas the database structure and management system will still be mongo. Not sure if it’s possible to run another DBMS in our application ecosystem.
Anything is possible of course but it looks to be high level work to replace the database connections and apis. Perhaps Tom and Jordin would like to have a chat here as maybe Jordin has some ideas on how we could switch the DB over (bearing in mind that we are very light on team members to complete that task right now).
Removing listIndexes calls from our codebase
I’ve posted around asking if anyone can see if its possible. Here’s a summary of the responses:
- A global search of
listIndexesin your project after opening it in gitpod yields no results (though it may be called byensureIndex). This is a total shot in the dark, but make sure you’re not using the admin database for your application - i.e. that the database name at the end of your mongodb connection string is not “admin”.
Me: From what i understood Atlas doesn’t allow listIndexes calls at the lower price plans
I disagree with that, I can do that on my completely free atlas plan. I think the problem comes from somewhere else (maybe the “admin” database being accessed in the code)
- Could this
_ensureIndexbe the problem? I think that may be calling intolistIndexeshere: https://github.com/mongodb/node-mongodb-native/blob/2b18411d2f57e06d11262d5a308c56a9f561789e/lib/operations/db_ops.js#L305. IIRC,ensureIndexis deprecated, and you should usecreateIndexinstead. I’m not familiar with meteor, so I’m not exactly sure what that code looks like, but the README shows how to access the underlying MongoDB driver directly: https://github.com/meteor/meteor/tree/devel/packages/mongo#direct-access-to-npm-mongodb-api. Hope that helps! - I know MongoDB and NodeJS reasonably well but React and Meteor not at all. That said, it looks like this line is what is interrogating the indexes (calling
listIndexeson the MongoDB collection):
Events._ensureIndex({ 'address.location': '2dsphere' })
I would suggest commenting out that line to see if it resolves the issue. Obviously it’s creating an index that is required so searching by address.location in the Events collection may be slow - depending on the number of records in the collection - until you can find a proper fix.
Also I can’t find anything in your links discussing the MongoDB issue, it appears to have been discussed in another location or offline. The guy that found the issue (mcnulty?) should provide a full stack trace of the error, this should show the error message and details and the exact line of the failure and the call stack. That would aid greatly anyone helping you.
Other Possibilities:
AWS Dynamob
AWS has dynamodb which is not a drop in replacement, it would require reworking stuff. But if your app is written in a way where you can rewrite the interface then you could gain very cheap Mongo-like database hosting with the ability to have it manage its own infrastructure and completely remove that complexity layer from you.
Update 2:
I’ve checked your Atlas org and I can see you’re currently running 2 x M2 Atlas instances (link). I’m also aware you believe the problem you’re facing is related to ‘listindex’ calls which you believe are not working against your databases.
It’s unclear exactly what the problem is or how it manifests, however, I’ve been able to connect to my own M2 instance (via the ‘mongo’ shell) and have successfully run a ‘listIndexes’ call as follows:
MongoDB Enterprise m2-shard-0:PRIMARY> db.runCommand({listIndexes:“details”})
{
"cursor" : {
"id" : NumberLong(0),
"ns" : "mydb.collection",
"firstBatch" : [
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "mydb.collection"
}
]
},
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1618489385, 10),
"signature" : {
"hash" : BinData(0,"ifKeZ4iMZcQ0oYcvlpdWPdIEI9c="),
"keyId" : NumberLong("6889736062340431876")
}
},
"operationTime" : Timestamp(1618489385, 10)
}
Is that what you are seeing? Or are the other problems that are presenting? If so, please provide additional details and, if possible, show what the commands and output / error you’re getting.